

Anthropic has introduced its latest AI model, Claude 3.7 Sonnet, showcasing its capabilities by testing it on the classic Game Boy title, Pokémon Red. This innovative approach highlights the model’s advanced features and offers insights into its performance.
Testing Claude 3.7 Sonnet with Pokémon Red
In a recent blog post, Anthropic detailed how Claude 3.7 Sonnet was evaluated using Pokémon Red. The model was equipped with basic memory, screen pixel input, and function calls to simulate button presses, enabling it to navigate the game’s environment. This setup allowed Claude 3.7 Sonnet to play the game continuously, demonstrating its ability to process visual inputs and execute complex sequences of actions.
Advancements in Extended Thinking
A standout feature of Claude 3.7 Sonnet is its “extended thinking” capability. This allows the model to engage in deeper, step-by-step reasoning, allocating more computational resources and time to analyze complex problems before responding. This deliberate approach enhances performance in areas like mathematics, physics, and coding, closely mimicking human contemplative thought.
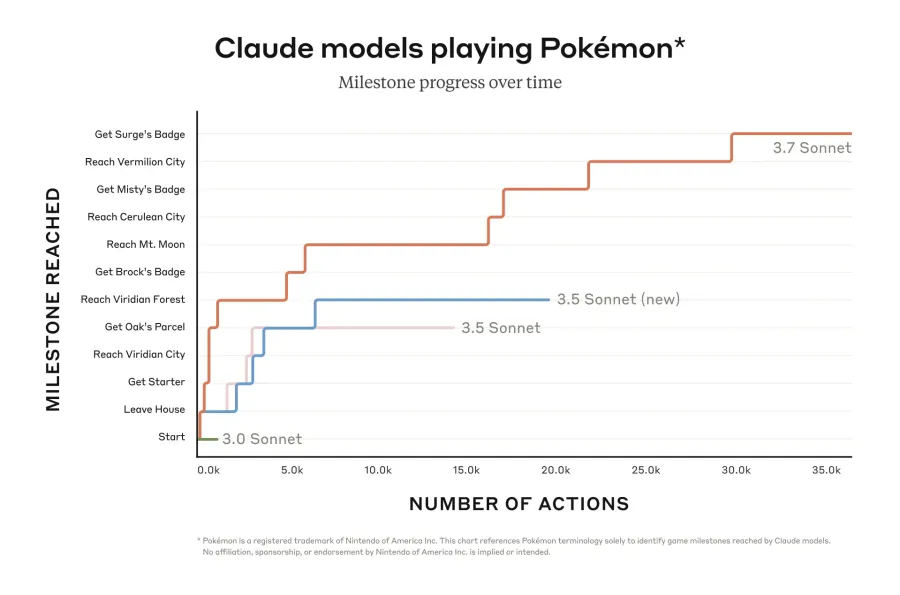
Performance Milestones in Pokémon Red
The practical application of extended thinking was evident during the Pokémon Red benchmark. While the previous version, Claude 3.0 Sonnet, struggled to progress beyond the initial stage in Pallet Town, Claude 3.7 Sonnet successfully defeated three gym leaders, earning their badges. This achievement underscores the model’s improved strategic planning and adaptability. Anthropic reported that the model performed 35,000 actions to reach the third gym leader, Lt. Surge.
Games as AI Benchmarks
Utilizing video games like Pokémon Red as benchmarks is part of a broader tradition in AI research. Games provide structured environments that test an AI’s decision-making, problem-solving, and learning abilities. Recently, various applications and platforms have emerged to evaluate AI models’ performance on games ranging from Street Fighter to Pictionary, reflecting the ongoing trend of using interactive challenges to assess and enhance AI capabilities.
Anthropic’s use of Pokémon Red to benchmark Claude 3.7 Sonnet not only showcases the model’s advanced reasoning and problem-solving skills but also highlights the effectiveness of using gaming environments to evaluate and drive AI development.
Frequently Asked Questions
Why did Anthropic choose a Pokémon game to evaluate Claude 3.7 Sonnet?
Pokémon games offer a complex environment with strategic depth, making them suitable for assessing an AI’s reasoning and decision-making capabilities.
How did Claude 3.7 Sonnet perform in the Pokémon game compared to previous models?
Claude 3.7 Sonnet demonstrated significant improvements over its predecessor, Claude 3.5 Sonnet, by advancing further in the game and defeating multiple gym leaders, whereas Claude 3.5 struggled to progress beyond the initial stages.
What specific tasks within the Pokémon game were used to test the AI model?
The AI was tested on its ability to navigate the game world, make strategic decisions during battles, and manage resources effectively to progress through various challenges.
What does this evaluation reveal about Claude 3.7 Sonnet’s capabilities?
The evaluation indicates that Claude 3.7 Sonnet possesses enhanced problem-solving skills, strategic planning, and adaptability in dynamic scenarios, reflecting its advanced reasoning abilities.
How does this gaming evaluation relate to real-world applications of AI?
Success in complex games like Pokémon suggests that the AI model can handle intricate decision-making tasks, which are applicable in fields such as finance, legal analysis, and autonomous systems.
Were there any limitations observed in Claude 3.7 Sonnet during the evaluation?
Claude 3.7 Sonnet showed marked improvements, it still lacks real-time web search capabilities, which could limit its access to the most current information.
How does Claude 3.7 Sonnet’s performance compare to human players in the Pokémon game?
The AI demonstrated advanced strategies and progression, direct comparisons to human players were not detailed. However, its ability to defeat multiple gym leaders indicates a high level of proficiency.
What are the implications of this evaluation for future AI development?
The positive results suggest that integrating complex game-based evaluations can effectively measure and enhance AI models’ reasoning and decision-making skills, guiding future advancements.
Is Anthropic planning to use similar evaluations for future AI models?
Specific plans haven’t been disclosed, the success of this evaluation may encourage Anthropic to continue using game-based assessments to benchmark and improve future AI models.
Where can I find more information about Claude 3.7 Sonnet and its evaluation?
You can refer to Anthropic’s official announcements and recent news articles covering Claude 3.7 Sonnet’s release and performance evaluations.
Conclusion
Anthropic evaluated its latest AI model, Claude 3.7 Sonnet, by testing its performance in a Pokémon game. This evaluation demonstrated significant advancements in the model’s reasoning and problem-solving capabilities. In internal tests, Claude 3.7 Sonnet was able to progress through the game by defeating multiple gym leaders, whereas its predecessor, Claude 3.5 Sonnet, struggled to move beyond the initial stage, Pallet Town. This improvement highlights the model’s enhanced ability to understand and navigate complex tasks, reflecting its potential for broader applications in areas requiring advanced reasoning and strategic planning.
This approach aligns with recent research from the Georgia Institute of Technology, where an AI agent named PokéLLMon was developed to achieve human-level performance in Pokémon battles. PokéLLMon incorporates strategies such as in-context reinforcement learning and knowledge-augmented generation to refine its decision-making and reduce errors. In online battles, it achieved a 49% win rate in ladder competitions and a 56% win rate in invited matches, showcasing the effectiveness of using game-based evaluations to enhance AI reasoning and strategic capabilities.
These findings suggest that using complex, strategy-based games like Pokémon as testing grounds can effectively measure and improve AI models’ reasoning and decision-making skills, potentially leading to more sophisticated and versatile AI applications.